
Designing DNA with AI
Using deep learning models to build synthetic enhancers.

Genomics is the study concerned with the function and mapping of genomes. By mapping, it means to identify and record the location of genes and the distances between genes on a chromosome. With the completion of the Human Genome Project and the Telomere-to-Telomere Consortium, the human genome has been entirely mapped. While the mapping of the genome is an extremely impressive feat, it has not led to an increase in the development of treatments.
This is because there is a stark difference between knowing a sequence of DNA and understanding its function. In biology there is something called the central dogma, stating that genetic information flows only in one direction, from DNA to RNA in the process of transcription, and RNA to protein in the process of translation.
While it may seem that we can easily understand the role of DNA by simply seeing what proteins they are producing, this is not exactly the case. When researchers analyzed what genetic mutations are associated with disease, they actually found out that the majority of mutations come from outside of the region of the genome that partakes in the process of transcription. In other words, the DNA that actually transcribe RNA are not the ones causing genetic mutations but are instead being affected by other mutated DNA. Thus, it becomes far more difficult to truly understand the function of DNA if its role can be influenced by other DNA.
In order to understand the function of DNA, we need to examine what the genome encodes. In addition to genes, the genome also encodes a complex regulatory code, an intricate network of regulator elements that controls gene regulation or when and how fast the process of transcription and translation happens. The regulatory code includes elements such as promoters, enhancers, silencers, transcription factors, and non-coding RNAs. These elements work together to regulate the timing, and specificity of gene expression in different cell types, developmental stages, and environmental conditions.
Because of this regulatory code, a single genome is capable of creating the enormous variety of cells that comprise the human body. If we can understand what DNA is activated to produce a certain protein, we can hopefully pinpoint and understand their function.
Sequencing-based technologies have recently been adopted to study gene regulation and enable genome-wide profiling of many features involved in the process of gene expression. Several research groups have now built highly accurate Machine Learning models that can quantitatively predict various aspects of gene regulation directly from a sequence of DNA.
One of the research groups actively using machine learning models is a group led by Ibrahim I. Taskiran from the laboratory of Stein Aerts in Belgium. The group's goal was to create enhancers that are specific to certain types of cells. They believed that deep learning models could help in designing these synthetic enhancers. This would enable them to study enhancer features in great detail at the level of individual nucleotides.
So what does it actually mean to design a cell-type specific enhancer? First, we need to define some terms. Genes have a special section that has the code for the protein that they produce. Just before this section, there is the promoter region. Proteins involved in the transcription process bind to the promoter. One key protein in this region is the RNA polymerase, which is responsible for creating the RNA molecule.
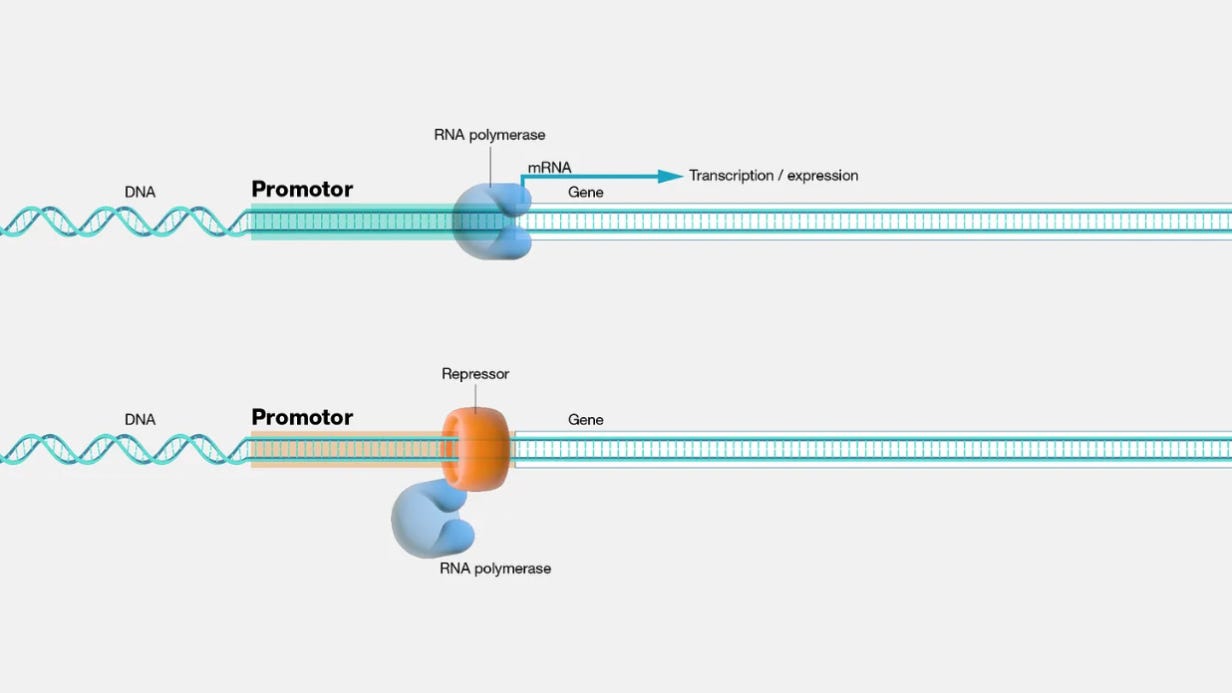
Finally, we also have enhancers, a specific region of DNA that regulates specifically the transcription process. The most important thing to understand is that enhancers are able to control where genes are turned on in time and space.
With an abundance of modern sequencing data, it has become possible to develop highly accurate machine learning models that can be used to control enhancers. In this study, the research team used these machine learning models to guide the design of totally new enhancer sequences that expressed genes only in specific cells. They tried three different design strategies, and tested their performance using fruit flies and human cells. The experiment involved creating a new enhancer sequence and inserting it into a fly.
They then used a microscope to see if this enhancer caused the reporter gene to be expressed specifically in certain types of cells. The most successful and elegant strategy was the first design, with the process beginning by generating 500 random bases of DNA.
Next, they performed saturation mutagenesis, meaning that every base in the sequence would be modified. The lab would then use their deep learning model to predict every possible mutation. The mutation that shows the best result in activating the desired cell type will be selected. They will keep repeating this process until the enhancer sequence consistently shows high predictions for their target.
Amazingly, it only took 15 mutations to go from the minimum score to the maximum score. This provides an interesting understanding of how enhancers can evolve naturally and emerge relatively quickly. It was also impressive how they were able to rapidly create effective enhancers. This study showed the huge potential of the intersection between AI and biology. Personally, I am very excited about our future.
Sources:
https://www.biorxiv.org/content/10.1101/2022.07.26.501466v1
https://centuryofbio.com/p/designing-dna-with-ai